
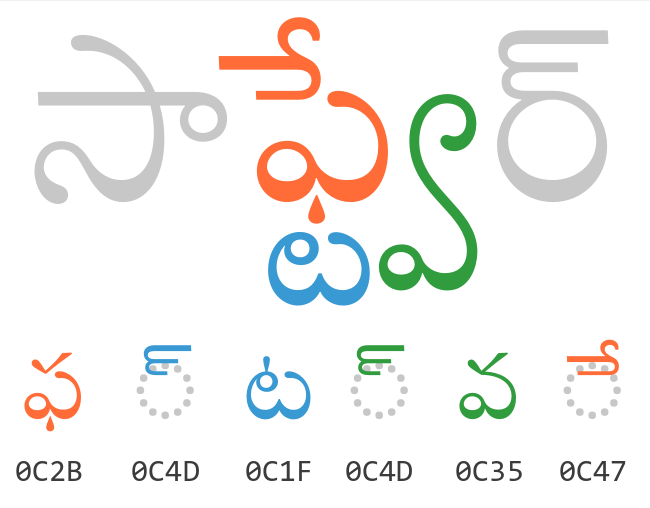
యూనికోడ్ – తెలుగు
-డా||కె.గీత
కిందటి నెలలో తెలుగు టైపు ప్రాథమిక దశ గురించి చెప్పుకున్నాం కదా! కీ బోర్డుల గురించి ప్రధాన విషయాలు తెలుసుకోవడానికి ముందు తెలుగు టైపులో యూనికోడ్ అనే అంశం గురించి తెలుసుకుందాం.
అసలు యూనికోడ్ అంటే ఏవిటి, అవసరం ఏవిటి అనేది చూస్తే తెలుగు లిపిని టైపు రైటర్ల మీద టైపు కొట్టినట్టు కంప్యూటర్ లో టైపు కొట్టగలిగినా ఇంతకు ముందు చెప్పినట్లు ఒక చోట టైపు చేసి ఫైళ్లలోదాచుకున్నది మరో చోట చదవాలంటే అన్ని చోట్లా తెలుగు లిపికి సంబంధించిన సపోర్టు ఉండాలి. అంతెందుకు టైపు కొట్టినది మార్జిన్లు వగైరా ఏ మాత్రం చెడకుండా ఉండేందుకు వాడే పిడిఎఫ్(PDF-Portable Document Format) రూపంలోకి తెలుగు లిపిలో టైపు కొట్టిన ఫైలుని మార్చాలన్నా సపోర్టు ఉండాలి.
1991 లో పేపరు నుండి డిజిటల్ రూపంలోకి ఫైళ్లని మార్చడానికి పిడిఎఫ్ ని అడోబీ (Adobe) ప్రపంచానికి పరిచయం చేసింది. ఇలా మార్చేటపుడు కాగితమ్మీద ఉన్న ప్రతి చిన్న వివరం అచ్చు గుద్దినట్టు బొమ్మగా మార్చగలుగుతుంది ఈ పిడిఎఫ్. అయితే తొలినాళ్లలో తెలుగు లిపిలో ఒక చోట టైపు కొట్టగలిగినా ప్రింటు తీసుకోవడానికి, కంప్యూటరులోనే మరే చోటి నుంచయినా తిరిగి ఫైలు తెరిచి చదవడానికి కుదిరేది కాదు. అంటే తలకట్లు దీర్ఘాలే కాదు అసలు ఏ భాషో తెలీని వింత రాతలు, డబ్బాలు కనిపించేవి. ఇందుకు కారణం ఏవిటంటే ఇంతకు ముందు చెప్పుకున్నట్టు ఒక కంప్యూటర్ నుండి ఇంకొక కంప్యూటర్కు డేటా ఇచ్చి పుచ్చుకొనేందుకు వీలుగా ఉండేందుకు ఒక్కొక్క అక్షరానికి ఇవ్వవలసిన స్థిరీకరణ కోడ్ అన్ని చోట్లా పనిచేసే కోడ్ కాదన్న మాట.
యూనికోడ్ కాని అక్షరాలు ఎలా కనిపిస్తున్నాయో ఉదాహరణ చూడండి:

“తొలితరం తెలుగు వెబ్ సైట్లు ముందు పేజ్ మేకర్ అనే డీటీపీ సాఫ్టువేర్ వాడి, సదరు పేజిని ఒక చిత్ర రూపంలో సేవ్ చేసి అప్పుడు వెబ్ పేజీలో పెట్టాల్సి వచ్చేది. లేకుంటే ఆ పేజ్ మేకర్ ఫైలును పిడీఎఫ్ ఫైలుగా మార్చి అయినా ఇంటర్నెట్ లో పెట్టాల్సి వచ్చేది. అప్పటికే డీటీపీ రంగంలో ప్రజాదరణ పొందిన అను ఫాంట్స్, శ్రీలిపి ఫాంట్స్నే వెబ్ సైట్లకొరకు కూడా వాడేవారు. దీని వల్ల చాలా సమస్యలు ఎదురయ్యేవి. మొదటిది, ఇలా ప్రతీది చిత్ర రూపంలోనో, పీడిఎఫ్ లోనో పెట్టడం వల్ల ఫైలు సైజు విపరీతంగా పెరిగిపోయి పాఠకులకు ఆ పేజి చాలా ఆలస్యంగా డౌన్ లోడ్ అయ్యేది. ఒకసారి చిత్రంలా మార్చిన దానిలో మార్పులు చేర్పులు చేసే అవకాశం వుండేది కాదు. ఇక డీటీపీ సాఫ్టువేర్ లో కీబోర్డ్ కొంచెం క్లిష్టంగా వుండటం వల్ల దాంట్లో టైపు చెయ్యడం చాలమందికి కష్టమయ్యేది.
ప్రభుత్వరంగ సంస్థ అయిన ‘సి డాక్’ ఈ రంగంలో చాలా కృషి చేసి అన్ని భారతీయ భాషల్లోను పని చేసే ఫాంట్స్ తో కూడిన ఐ-లీప్ అనే పాకేజీని అభివృద్ధి పరచింది. కాని ఎందుకో అది అంతగా ప్రాచుర్యం పొందలేదు. బహుశా ఐ-లీప్ సాఫ్ట్ వేర్ డబ్బులు పెట్టి కొనుక్కోవలసిరావడం ఇది అంతగా ప్రాచుర్యం పొందకపోవడానికి కారణమయి ఉంటుంది.
కొంత కాలానికి తెలుగు వార్తా పత్రికలు ఎవరికి వారు డైనమిక్ ఫాంట్లు అభివృద్ధి పరచుకోవడం మొదలుపెట్టారు. వీటి వల్ల సమస్య కొంచెం పరిష్కారం అయినా, అందరికీ ఈ డైనమిక్ ఫాంట్లు వాడే వీలు లేకపోవడం, కీబోర్డ్ అంతగా సులువుగా లేకపోవడం వల్ల ఈ టెక్నాలజీ కొన్ని ఇంటర్నెట్ పత్రికల దగ్గరే ఆగిపోయింది.
ఇప్పుడు యూనికోడ్ టెక్నాలజీ ప్రాచుర్యంలోకి వచ్చింది. దీని గొప్పతనం ఏమిటంటే ఇది ఉపయోగించి ఏ భాషలోనైనా టైపు చెయ్యవచ్చు, దానిని ఇతర కంప్యూటర్లకు పంపించవచ్చు, వెబ్ పేజీలు తయారు చెయ్యవచ్చు. మైక్రోసాఫ్ట్ విండోస్ 2000 నుంచి పూర్తిగా యూనికోడ్ ను సపోర్టు చెయ్యడం మొదలవటంతో ఇక ఈ రంగంలో కదలిక మొదలైంది.” (కొణతం దిలీప్, తెలంగాణా మాస పత్రిక)
సూక్ష్మంగా చెప్పాలంటే యూనీకోడ్ అంటే అన్ని చోట్లా పనిచేసే స్థిరీకరణ కోడ్ అన్న మాట. దీన్నే తెలుగులో సర్వ సంకేత పద్ధతి అని, ఏకరూప సంకేత పద్ధతి అని అంటున్నారు.
“కంప్యూటర్లు ప్రధానంగా అంకెలతో పని చేస్తాయి. ఒక్కో అక్షరానికీ, వర్ణానికీ ఒక్కో సంఖ్యని కేటాయించి నిక్షిప్తం చేసుకొంటాయి. యూనీకోడ్ కనుగొనబడక ముందు, ఈ విధంగా సంఖ్యలని కేటాయించడంకోసం వందలకొద్దీ సంకేతలిపి (encoding) పద్ధతులు ఉండేవి. ఏ ఒక్క పద్ధతిలోనూ చాలినన్ని వర్ణాలు ఉండేవికాదు: ఉదాహరణకు, ఒక్క ఐరోపా సమాఖ్య లోని భాషలకోసమే చాలా సంకేతలిపి పద్ధతులు కావలసి వచ్చేవి. అంతెందుకు, ఒక్క ఇంగ్లీషు భాషలోని అన్ని అక్షరాలు, సాధారణ వాడుకలో ఉన్న వ్యాకరణ, సాంకేతిక వర్ణాలకే ఏ ఒక్క సంకేతలిపి పద్ధతీ సరిపోయేది కాదు.
ఆ సంకేతలిపి పద్ధతుల మద్య వైరుధ్యాలుకూడా ఉండేవి. అంటే, వేర్వేరు పద్ధతులు ఒక సంకేతసంఖ్యని వేర్వేరు అక్షరాలకు, లేదా వేర్వేరు సంకేతసంఖ్యల్ని ఒకే అక్షరానికి ఉపయోగించేవి. కంప్యూటర్లు (ముఖ్యంగా సర్వర్లు) చాలా రకాలైన సంకేతలిపి పద్ధతులకు అనువుగా ఉండవలసి వచ్చేది; అయినా సరే, వివిధ సంకేతలిపి పద్ధతుల లేదా ప్లాట్ఫామ్ ల మధ్య డేటా ప్రయాణించినప్పుడు, ఆ డేటా చెడిపోయే ప్రమాదం ఎప్పుడూ పొంచి ఉండేది.
ప్రతీ అక్షరానికీ ఓ ప్రత్యేక సంఖ్యని యూనీకోడ్ అందిస్తుంది. ప్లాట్ఫామ్ ఏదైనా, ప్రోగ్రామ్ ఏదైనా, భాష ఏదైనా సరే. ఒకే సాఫ్ట్వేర్ ఉపకరణము లేదా ఒకే వెబ్సైట్ వివిధ ప్లాట్ఫామ్లకు, భాషలకు, దేశాలకు పనికివచ్చేవిధంగా (మళ్ళీ మళ్ళీ తయారుచేసే అవసరం లేకుండానే) యూనీకోడ్ సుసాధ్యం చేస్తుంది. అనేక సిస్టముల మధ్య రవాణాలో డేటా చెడిపోకుండా ఇది వీలు కల్పిస్తుంది.” (వీవెన్, యూనీకోడ్ డాట్ ఆర్గ్)
“ప్రపంచవ్యాప్తంగా సమాచార మార్పిడికి ప్రమాణ బద్ధమైన వ్యవస్థగా యూనికోడ్ ను ఆమోదించారు. భారతీయభాషల కోసం ఐ.ఎస్.ఐ.ఐ-88 లో అవసరమైన మార్పులు భారత ప్రభుత్వం యూనికోడ్ కన్సార్టియం సహాయంతో రూపుదిద్దడమే కాకుండా కేంద్ర ఇన్ఫర్మేషన్ టెక్నాలజీ శాఖ యూనికోడ్ కన్సార్టియం లో పూర్తికాలం ఓటింగ్ హక్కుతో కూడిన సభ్యత్వాన్ని పొందింది.” (వికాస్ పీడియా)
“యూనీకోడ్ కన్సార్టియం” అంటే “యూనీకోడ్ ప్రమాణపు అభివృద్ధి, వ్యాప్తి, విస్తృతికై ఏర్పాటైన లాభాపేక్షలేని సంస్థ”. ఈ ప్రమాణం ఆధునిక సాఫ్ట్వేర్ ఉత్పత్తులు, ప్రమాణాలలో వచన ఉపయోగ విధానాన్ని నిర్దేశిస్తుంది. కంప్యూటరు & సమాచార ఆధారిత పరిశ్రమకు చెందిన విభిన్న వ్యాపార, స్వచ్ఛంద సంస్థలు ఈ సంస్థలో సభ్యులుగా ఉన్నాయి. ఆర్థికపరంగా పూర్తిగా సభ్యత్వ రుసుము మీదే ఆధారపడి సంస్థ నడుస్తుంది. యూనీకోడ్ ప్రమాణాన్ని అమలుపరిచే మరియు దాని వ్యాప్తికి, అమలుకు తోడ్పడాలనుకునే అన్ని సంస్థలు మరియు వ్యక్తులు, ప్రపంచంలో ఎక్కడున్నా, యూనీకోడ్ కన్సార్టియంలో సభ్యత్వం పొందవచ్చు.” (యూనీకోడ్ డాట్ ఆర్గ్)
“అక్షరాలు, చిహ్నాలు, అంకెలను సంకేతాలుగా రూపొందించడంలో యూనికోడ్ రూపొందించిన ప్రమాణం ప్రపంచవ్యాప్తంగా ఆమోదయోగ్యమైంది. టెక్స్ట్ ను కంప్యూటర్లో ప్రాసెస్ చేయడానికి యూనికోడ్ ప్రమాణాన్ని ఉపయోగిస్తారు. ప్రపంచంలోని అన్ని లిఖిత భాషల అక్షరాలు, చిహ్నాలు, అంకెలను సంకేతరూపంలోనిర్మించేందుకు కావలసిన సామర్థ్యాన్ని యూనికోడ్ ప్రమాణాలు అందజేస్తాయి. బహుభాషల టెక్ట్స్ కోసం వినియోగించే వారికే కాకుండా, కంప్యూటర్ వినియోగించే వ్యాపారవర్గాలు భాషావేత్తలు, పరిశోధకులు, శాస్త్రవేత్తలు, సాంకేతిక నిపుణులకు యూనికోడ్ ప్రమాణాలు ఎంతో ఉపయోగకరం.
యూనికోడ్ 16 విభాగాల సంకేత నిర్మాణ ప్రక్రియను ఉపయోగిస్తుంది. 65 వేలకు పైగా అక్షరాలకు చిహ్నాలకు, అంకెలకు యూనికోడ్ సంకేత రూపం ( నోడ్ పాయింట్) కల్పిస్తుంది. యూనికోడ్ స్టాండర్డ్ , ఐ. ఎస్. ఓ -10646 స్టాండర్డ్ కలిసి యు. టి.ఎఫ్ -16 అనే అదనపు వ్యవస్థను అందిస్తాయి. దాదాపు పదిలక్షల అక్షరాలు, చిహ్నాలు, అంకెలకు సంకేత రూపం (క్యారెక్టర్ ఎన్ కోడింగ్ ) కల్పిస్తుంది.” (వికాస్ పీడియా)
“క్యారెక్టర్ ఎన్ కోడింగ్” అంటే అక్షరాలను కంప్యూటర్ కు బైట్ల రూపంలో మార్చగలిగే నిర్దేశికత్వాల్ని తెలియజేస్తుంది.
ఒక విధంగా ఆలోచిస్తే యూనీకోడ్ అనేది కంప్యూటర్ చరిత్రలో భాషలకు సంబంధించి ఒకానొక గొప్ప మైలురాయిగా చెప్పదగిన విప్లవం.
“తొలితరం తెలుగు సైట్లలో చాలా తక్కువ సైట్లు మాత్రమే తెలుగు లిపిని ఉపయోగించేవి. తెలుగు లిపిని వెబ్ పేజీలలో చూపించడానికి ప్రామాణికమైన పద్ధతి లేకపోవడం, తెలుగులిపిని బొమ్మల రూపంలో చూపే సైట్లు నడపడానికి కష్టం కావడంతో అవి తొందరగా మూతపడేవి. తెలుగు వంటి ఆంగ్లేతర భాషల/లిపుల కోసం ప్రత్యేకంగా సంకేత స్థలాలను కేటాయించే యూనికోడ్ ప్రమాణం (Unicode) 1991 నుండే అభివృద్ధి చెందినా, దానిని సమర్థించే (support) నిర్వహణా వ్యవస్థ (Operating System) లేకపోవడంతో 2003 వరకు యూనికోడ్ ప్రమాణాన్ని తెలుగు కోసం వాడుకోనే వీలు లేకపోయింది. కానీ, తెలుగు లిపిని కంప్యూటర్ తెరపై చూపడానికి, టైపు చెయ్యడానికి అవసరమైన వ్యవస్థను, వనరులను 2003లో Microsoft XP ఆపరేటింగ్ సిస్టమ్ లోనే పొందుపరచడంతో కంప్యూటర్లపై తెలుగు రాయడం, చదవడం ఎన్నడు లేనంతగా సుళువయ్యింది. తెలుగులో ఈమెయిళ్ళు రాసుకోవడానికి, తెలుగు లిపిని ఉపయోగించి వెబ్సైట్లను నిర్మించడానికి, తెలుగు చర్చావేదికలకు, ఇంటర్నెట్టులోనే వెతకగలిగే తెలుగు డిక్షనరీల నిర్మాణానికి యూనీకోడ్ సరికొత్త ద్వారాలను తెరిచింది. యూనికోడ్ టెక్నాలజీతో పాటు, Web 2.0 ఇంటరాక్టివ్ ఫీచర్లు అందరికీ అందుబాటులోకి రావడంతో, తెలుగు బ్లాగులు, కొత్త తరం తెలుగు పత్రికలు, తెలుగు వికీపీడియా వంటి బృహత్తర ప్రాజెక్టులకు మార్గం సుగమమయ్యింది.” (సురేశ్ కొలిచాల, ఈ-మాట)
“కంప్యూటర్లలో తెలుగు భాష వాడకం మొదలైంది 1993 ప్రాంతంలో ముద్రణా రంగంలో వచ్చిన అనివార్య సాంకేతిక అభివృద్ధి వల్లే. డిటిపి అప్లికేషన్లు తయారవడం, వాటిల్లో వాడటానికి తెలుగు ఫాంట్లు రూపొందించడం, ఇలా తయారైన పేజీలను ముద్రించడానికి లేజర్ ప్రింటర్లు లాంటి అత్యాధునిక పరికరాలు రావడంతో డెస్క్టాప్ పబ్లిషింగ్ శరవేగంగా అభివృద్ధి సాధించింది. ఎప్పుడైతే ఇంటర్నెట్ రంగప్రవేశం జరిగిందో, అప్పటినుంచే ప్రాంతీయ భాషలను కూడా అంతర్జాలంలో ప్రవేశపెట్టే ప్రయత్నాలు మొదలయ్యాయి. అయితే ఫాంట్లను వెబ్ పేజీల్లోకి చొప్పించడం ప్రయాసతో కూడుకున్న వ్యవహారం కావడం, చదివేవారికి కూడా సాంకేతిక అవగాహన కావాల్సి రావడంతో అంతగా ఆ ప్రయత్నం విజయవంతం కాలేకపోయింది. యూనీకోడ్ ఫాంట్ల (ఏకసంకేత ఖతులు లేదా విశ్వరూప ఖతులు) ప్రవేశం అంతర్జాల భాషావినియోగాన్ని సమూలంగా మార్చివేసింది. ప్రపంచలోని లిపియుక్త భాషలన్నింటికీ అంతర్జాల ప్రవేశాన్ని కల్పించి, వాటి ఉనికిని కూడా కాపాడగలిగింది. ఇప్పుడు తెలుగు భాషలో మంచి యూనీకోడు ఫాంట్లు అభివృద్ధి చేశారు. అందమైన అక్షరాలు రకరకాల పరిమాణాల్లో రూపొందించారు వీటిలో చాలా వరకు ఉచితంగా లభిస్తాయి. తెలుగు భాష అక్షరాలకు ఈ క్రింది యూనీకోడు బ్లాకు ఇవ్వబడింది 0C00-0C7F (3072-3199).” (యూనీకోడ్ డాట్ ఆర్గ్)
యూనికోడ్ కంప్యూటర్ కు లిపి సంబంధిత కోడ్ నిర్దేశికత్వం వహిస్తే, ఫాంట్ అనేది లిపిని కనిపింపజేయడానికి ఉపకరిస్తుంది. వచ్చేనెలలో ఫాంట్ల గురించి తెలుసుకుందాం.
*****

డా|| కె.గీత పూర్తిపేరు గీతామాధవి. వీరు “నెచ్చెలి” వ్యవస్థాపకులు, సంపాదకులు. తూ.గో.జిల్లా జగ్గంపేటలో జన్మించారు. ప్రముఖ కథా రచయిత్రి శ్రీమతి కె. వరలక్ష్మి వీరి మాతృమూర్తి. భర్త, ముగ్గురు పిల్లలతో కాలిఫోర్నియాలో నివాసముంటున్నారు.
ఆంధ్ర విశ్వవిద్యాలయంలోఇంగ్లీషు, తెలుగు భాషల్లో ఎం.ఏ లు, తెలుగు భాషా శాస్త్రం లో పిహెచ్.డి చేసి, 10 సం. రాల పాటు మెదక్ జిల్లాలో ప్రభుత్వ కళాశాల అధ్యాపకురాలిగా పనిచేసారు. ఆంధ్ర ప్రదేశ్ ప్రభుత్వం నించి 2006 లో “ఉత్తమ ఉపాధ్యాయ అవార్డు ” పొందారు.అమెరికాలో ఇంజనీరింగ్ మేనేజ్ మెంట్ లో ఎం.ఎస్ చేసి, ప్రస్తుతం సాఫ్ట్ వేర్ రంగంలో భాషా నిపుణురాలిగా పనిచేస్తున్నారు.
ద్రవభాష, శీతసుమాలు,శతాబ్దివెన్నెల, సెలయేటి దివిటీ, అసింట కవితాసంపుటులు, సిలికాన్ లోయ సాక్షిగా కథాసంపుటి, వెనుతిరగనివెన్నెల నవల, At The Heart of Silicon Valley -Short stories (2023),Centenary Moonlight and Other Poems(2023) ప్రచురితాలు. నెచ్చెలి ప్రచురణ “అపరాజిత” – గత ముప్పయ్యేళ్ల స్త్రీవాద కవిత్వం (1993-2022) పుస్తకానికి సంపాదకులు & ప్రచురణకర్త. ‘యాత్రాగీతం’ ట్రావెలాగ్స్, ‘కంప్యూటర్ భాషగా తెలుగు’ పరిశోధనా వ్యాసాలు కొనసాగుతున్న ధారావాహికలు. అజంతా, దేవులపల్లి, రంజనీ కుందుర్తి, సమతా రచయితల సంఘం అవార్డు, తెన్నేటి హేమలత-వంశీ జాతీయ పురస్కారం, అంపశయ్య నవీన్ పురస్కారం మొ.న పురస్కారాలు పొందారు.
టోరీ రేడియోలో “గీతామాధవీయం” టాక్ షోని నిర్వహిస్తున్నారు. తానా తెలుగుబడి ‘పాఠశాల’కు కరికులం డైరెక్టర్ గా సేవలందజేస్తున్నారు. కాలిఫోర్నియా సాహితీ వేదిక “వీక్షణం”, తెలుగు రచయిత(త్రు)లందరి వివరాలు భద్రపరిచే “తెలుగురచయిత” వెబ్సై ట్ వ్యవస్థాపకులు, నిర్వాహకులు.